
FADE IN:
INT. GARAGE - LATE NIGHT
A MECHANIC stares at the open hood of a hybrid Lamborghini. The engine bay is a maze of advanced components, carbon fiber, and million-dollar engineering. Tools are scattered across the floor alongside unidentifiable parts.
MECHANIC
(wiping grease-stained hands)
Eight hours to change the oil. Eight hours.
(looks at the scattered components)
Maybe I should just buy a whole new car.
The mechanic closes the hood with a frustrated SLAM.
FADE TO BLACK.This is the unmanaged experience of Apache Spark in 2025, and it is a Screen Play in length, you were warned! P.s. – Netflix greenlight me!
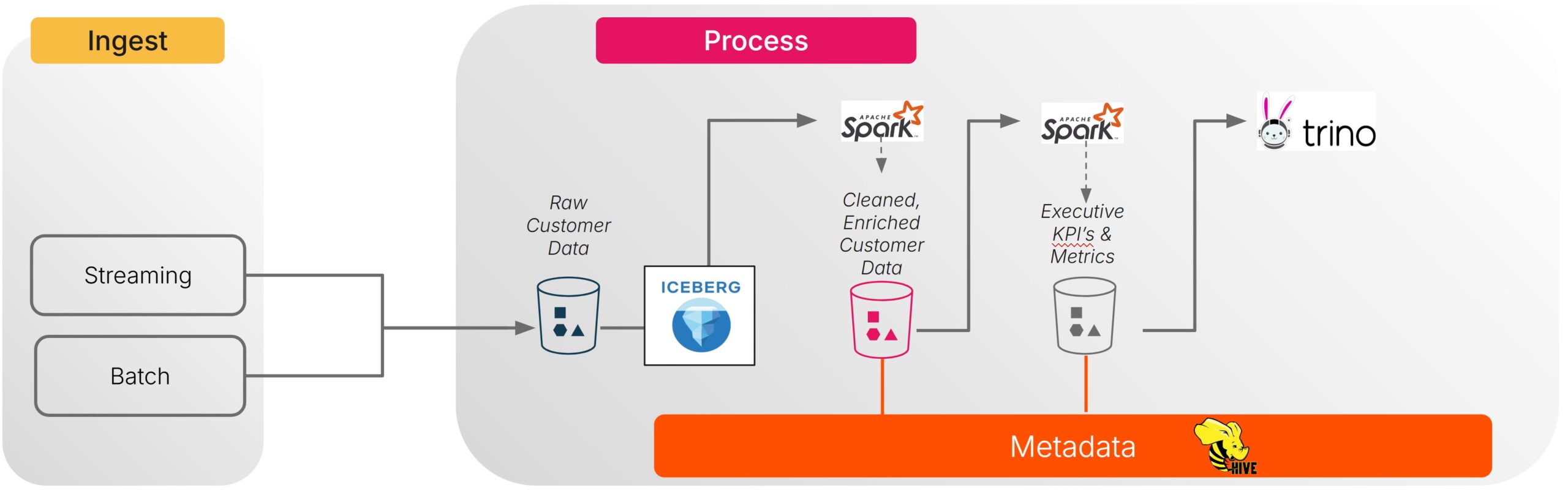
A few weeks ago, I dove deep into Apache Spark through hands-on implementation of a Customer 360 use case, using the medallion pipeline processing architecture (Bronze → Silver → Gold) using the Stackable operators on Kubernetes.
The full code and infrastructure deployment for this blog can be found at the GitHub Page for spark-lakehouse-medallion-pipeline
My goal wasn’t to benchmark Spark against the competition or showcase another managed Databricks demo. Instead, I wanted to understand how modern data processing really works in 2025, stripped of vendor marketing and managed service abstractions. It was also, honestly, really cool.
What I discovered fundamentally changed how I think about data engineering, while robbing me of what little sanity I had for a bit: Spark isn’t a product. It’s a component – and its dangerously time consuming if handled incorrectly.
The Scale-Out Revolution That Changed Everything (And Why We’re Still Dealing With It)
To understand why Spark matters in 2025, we need to step back to the big data period – circa 2012-2023. And no, I’m not going to subject you to another “data is the new oil” speech (funny how all the industry jargon is just the oil and gas jargon). The fundamental breakthrough wasn’t just about handling more data; it was about solving an architectural problem that still keeps data engineers up at night: scale-up versus scale-out.
BUT WHAT ABOUT DATABASES!!!!
Traditional databases are brilliant at scale-up architectures. Throw more CPU, more memory, faster storage at a single machine, and your queries get faster. It’s like souping up a sports car – more horsepower, better performance. This works beautifully until you hit the physics limits of what one machine can do. (Spoiler alert: those limits arrive faster than you think.)
Where this all really started: The MapReduce revolution introduced scale-out processing: distribute your computation across dozens, hundreds, or thousands of machines. Suddenly, you could process datasets that would make a single machine weep. But MapReduce was brutally constrained – batch-only, disk-based processing with a rigid two-stage model that made even simple analytics feel like performing surgery with oven mitts.
Silli’s fun facts – MapReduce is an architecture MapR was aquired by HPE in 2019, which implemented Hadoop stacks that included Spark as a component.
Spark emerged as the natural evolution of this distributed computing universe. It moved beyond MapReduce’s limitations into a general-purpose, DAG-based framework that could handle complex multi-stage analytics, unified batch and streaming processing, and leverage memory caching for iterative workloads. It wasn’t just faster than MapReduce; it completely reshaped how engineers thought about data pipelines.
Quick aside – Spark’s technical architecture for the layman
- Driver: The boss that coordinates everything and breaks your data job into smaller tasks
- Executors: The workers running on different machines that do the actual data processing in parallel
- DAG (Directed Acyclic Graph): A smart flowchart that figures out the most efficient order for your data transformations
- Memory caching: Instead of writing everything to disk between steps, Spark keeps intermediate results in memory (like a construction crew holding materials while building rather than constantly putting things down)
- Shuffle and spill: When executors need to share data with each other (like sorting or joining), they “shuffle” data across the network. When there’s not enough memory, Spark “spills” to disk, which is slow and expensive (imagine your construction crew constantly dropping tools and picking them up again)
The Cluster Mode Overview of Apache Spark is a particularly interesting deep dive on the topic.
Silli side note: I’m glossing over shuffle optimization here because that alone could fill another blog post. For now, assume there’s a magic wand making everything work perfectly – I am focusing on the broader complexity story, not every tuning parameter.
But here’s the critical insight: the innovations in scale-out processing are what’s really driving modern data architecture. Spark has become one of the most widely adopted frameworks for distributed data processing, powering everything from Netflix’s recommendation algorithms to Uber’s real-time analytics. While there are alternatives (Flink for streaming, Presto/Trino for interactive queries, various cloud-native engines), Spark’s versatility in handling batch, streaming, ML, and SQL workloads has made it the go-to choice for many organizations building data platforms in prior years.
Whether you love it or hate it, you’ve probably encountered it and also interacted with the engineers pulling their hair out with it.
The Real Battle: The Lakehouse Layer
During my time implemnted the use case (it was in a demo lab), I quickly realized that Spark’s raw computational power isn’t where the complexity lies. Oh no, that would be too easy. The real battle is at the lakehouse layer: wiring Spark into table formats like Iceberg, Hudi, or Delta Lake, and making it play nicely with object storage, catalogs, schedulers, and governance systems.
Quick lakehouse primer: A lakehouse combines the flexibility of a data lake (store any type of data in cheap object storage like S3) with the reliability and performance of a data warehouse (ACID transactions, schema enforcement, time travel queries). Think of it as putting a structured database layer on top of a massive file system. The “table formats” (Iceberg, Delta Lake, Hudi) are the magic that makes this work – they track metadata about your files so Spark can treat a bunch of Parquet files in S3 as if they were database tables with all the features you’d expect.
Silli’s Side note: This is one of my favourite subjects: the modern analytics architecture where all the fun in data processing is happening (and cough where a lot of AI modernization $ are being spent! *cough, *cough* databricks $100Bn valuation cough.

Technical Stuff!
Consider the seemingly simple task of reading customer data from S3, joining it with transaction history, and writing the results to an Iceberg table. “Simple,” you think. “I’ll have this done by lunch.” Fast forward to 6 PM, and you’re still debugging why your job is reading the same S3 object 47 times, why the solution does not scale, why the metastore has empty tables, or any number of other hair pulling scenarios I have encountered over the last few weeks.
Disclosure: This implementation uses Pure Storage FlashBlade as the object storage backend, configured to be S3-compatible. While I reference “S3” throughout for simplicity, the actual storage layer is FlashBlade providing S3 API compatibility.
Here’s where reality hits. Let me show you what my actual Stackable configuration looks like for this “basic” Customer 360 pipeline. This is just the Spark job configuration for connecting to storage and catalogs:
sparkConf:
# Iceberg and Hive integration (because nothing's ever just "Spark")
spark.jars.packages: "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1"
spark.sql.extensions: "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"
spark.sql.catalog.ice: "org.apache.iceberg.spark.SparkCatalog"
spark.sql.catalog.ice.type: "hive"
# S3A filesystem configuration (the fun part)
spark.hadoop.fs.s3a.endpoint: "http://10.21.227.158:80"
spark.hadoop.fs.s3a.path.style.access: "true"
spark.hadoop.fs.s3a.fast.upload: "true"
spark.hadoop.fs.s3a.multipart.size: "134217728"
spark.hadoop.fs.s3a.connection.maximum: "1024"
spark.hadoop.fs.s3a.threads.max: "512"
# And about 20 more parameters I'm not showing you...
Count those parameters. That’s just for basic S3 connectivity and Iceberg integration. We haven’t even talked about memory tuning, shuffle optimization, or the networking configurations that keep your jobs from mysteriously hanging.
Behind the scenes, you’re actually orchestrating:
- Storage optimization: Managing S3 throughput, handling eventual consistency (yes, it’s still a thing), optimizing partition layouts
- Compute Resource management: Sizing executors, configuring shuffle behavior, preventing those delightful out-of-memory errors that crash your job at 95% completion. Fun fact – I had to go from 2GB of memory per executor to 32GB because the underlying java heap kept failing. I can fully understand how these workloads in the cloud suddenly add 00’s to the end of that monthly cloud bill.
- Catalog integration: Ensuring schema evolution works with Hive Metastore or Glue (spoiler: it doesn’t always)
- Format compatibility: Handling time travel queries, compaction strategies, and metadata management. This is where data engineering gets real fun!
- Cluster orchestration: Dynamic resource allocation, fault tolerance, and job scheduling. Praise Our Saviour, Google, for giving us Kubernetes and taking down that old monster…YARN!
My Customer 360 pipeline required three separate Kubernetes deployments: PostgreSQL for the Hive Metastore, the Hive Metastore itself, Trino for analytics, plus separate SparkApplication manifests for each stage of the medallion pipeline. That’s before we even talk about the RBAC configurations, secret management, and S3 connection definitions.
Lets make this clear – I am not implementing RBAC, NO, NO, NO! Hack away lads.
To illustrate the data processing complexity, here’s a snippet from my bronze ingestion job that generates realistic customer interaction data. This looks simple enough – basic Python code generating customer records:
# Customer 360 raw interaction data generation
base_data = (spark.range(0, rows_total)
.withColumn("event_timestamp", expr("date_sub(current_timestamp(), cast(rand() * 30 as int))"))
.withColumn("customer_id", floor(rand() * 500000).cast("long"))
.withColumn("interaction_type", expr("case when rand() < 0.3 then 'purchase' when rand() < 0.5 then 'browse' when rand() < 0.7 then 'support' else 'abandoned_cart' end"))
.withColumn("transaction_amount", expr("case when interaction_type = 'purchase' then rand() * 1000 + 10 else 0 end"))
# ... plus about 30 more columns with realistic business logic
)Simple customer data generation, right? But here’s where the complexity explodes. This innocent-looking Python code requires a massive infrastructure configuration to actually run:
executor:
cores: 2
memory: 32Gi
instances: 64
env:
- name: MDP_INGEST_GB
value: "1024"
- name: MDP_INGEST_PARTITIONS
value: "768"
- name: MDP_TARGET_FILE_MB
value: "256"Each of these layers has its own configuration parameters, failure modes, and performance tuning requirements. Get one wrong, and your jobs stall, clusters thrash, or storage chokes. It’s like playing Jenga, but every block is on fire and the tower costs $10,000 per hour to keep standing.
The Component vs Product Reality
This complexity illuminates why I describe Spark as requiring gloves. It’s not dangerous because it’s obsolete – quite the opposite. It’s dangerous because it’s so powerful and so intricate that operational mistakes cascade quickly. It’s like giving someone the keys to a Formula 1 car and saying “good luck with the commute.”
When you deploy raw Apache Spark, you’re not getting a product; you’re getting a sophisticated component that needs extensive integration work. You need to wire it into:
- Container orchestration (Kubernetes operators, resource management, and the joy of YAML debugging)
- Storage systems (object stores, distributed file systems, and their delightful inconsistency guarantees)
- Metadata catalogs (Hive Metastore, AWS Glue, custom implementations that someone built in 2018 and nobody wants to touch)
- Security frameworks (authentication, authorization, network policies that make simple things impossible)
- Monitoring systems (metrics collection, job tracking, performance analysis, and alerts that wake you up at 3 AM)
- Development workflows (CI/CD pipelines, testing frameworks, deployment automation that works 60% of the time, every time)
Here’s what my “simple” medallion pipeline actually required in terms of infrastructure (fun fact it got 6 GB/s throughput on a minmal config Pure Storage FlashBlade//S200!):
# Just the PostgreSQL StatefulSet for Hive Metastore
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mdp-hms-postgres
spec:
template:
spec:
containers:
- name: postgres
env:
# PostgreSQL performance tuning (because default configs won't cut it)
- name: POSTGRESQL_SHARED_PRELOAD_LIBRARIES
value: "pg_stat_statements"
- name: POSTGRESQL_MAX_CONNECTIONS
value: "200"
- name: POSTGRESQL_SHARED_BUFFERS
value: "16GB"
- name: POSTGRESQL_EFFECTIVE_CACHE_SIZE
value: "6GB"
# Plus 15 more PostgreSQL tuning parameters...And that’s just the database that supports the metadata catalog that Spark needs to understand what tables exist. We haven’t even started the actual Spark jobs yet! This was important to show because the entire pipeline slowed down when it could not access the metastore quickly enough.
Looking at the current landscape of Spark deployment options illustrates this perfectly, and boy, do we have options:
| Option | What it is | Why teams pick it | Reality check |
| Kubeflow Spark Operator | Kubernetes operator for submitting Spark apps via CRDs | Cloud-agnostic, GitOps-friendly, integrates with K8s schedulers | Requires deep Kubernetes expertise (hope you like YAML!) |
| Native Spark on Kubernetes | Spark’s first-class K8s mode, direct from Apache | Lowest “Spark drift,” full control of versions/config | You handle ALL operational concerns yourself |
| Stackable operators | Composable operator platform for data infrastructure | Powerful composability, vendor-agnostic | Assumes significant infrastructure management capability (and infinite patience) |
| Google Cloud Dataproc on GKE | Managed Spark service running on your GKE clusters | Google-managed job API, faster spin-up, autoscaling | Good fit for Iceberg/Delta integration |
| AWS EMR | Managed Spark distribution with deep AWS integration | Tuned builds, per-second billing, mature Iceberg support | Because hourly billing is apparently too generous |
| Azure Synapse | Managed Spark pools with tight Azure integrations | Click-ops simplicity, native notebooks, built-in governance | Delta Lake is a first-class citizen |
| Databricks | Fully managed lakehouse platform with Photon engine | Strongest “lakehouse performance per $” story, minimal ops | Most complete platform but premium pricing |
The value isn’t in the vendor logo. What matters is how completely the operational complexity gets abstracted away. Do you want to spend your time building data products, or do you want to become an expert in shuffle partition tuning? Choose wisely.
Why Managed Services Command Premium Pricing
After wrestling with executor sizing, shuffle optimization, and S3 throughput tuning in my medallion pipeline, I finally understood why organizations pay significant premiums for managed Spark services. It’s not just about convenience; it’s about operational survival. And honestly, sanity preservation.
The “in-memory magic” marketing narrative around Spark misses the real story. Modern Spark workloads succeed or fail based on operational maturity: how well you tune resource allocation, handle failure scenarios, optimize storage access patterns, and integrate with the broader data ecosystem. The difference between a Spark job that runs in 10 minutes versus 3 hours often comes down to configuration parameters that require deep expertise to optimize.
Here’s what my silver enrichment job looks like in practice. Remember, this is supposed to be the “simple” data cleaning stage – just standardizing email addresses and adding some business logic:
# REALISTIC data cleaning - preserve most data while adding value
silver_df = (df_bronze
# Light filtering - only remove truly bad data (keeps ~95% of records)
.filter(col("data_quality_flag") != "duplicate_suspected")
# KEEP ALL ORIGINAL COLUMNS from Bronze for realistic size retention
# Add standardized/cleaned versions alongside originals
.withColumn("email_clean", regexp_replace(lower(trim(col("email_raw"))), "\\.duplicate", ""))
.withColumn("phone_clean",
regexp_replace(
regexp_replace(col("phone_raw"), "[^0-9]", ""),
"^1?(\\d{10})$", "($1)"
))
# Geographic standardization - keep originals and add cleaned versions
.withColumn("state_standardized",
when(upper(col("state_raw")).isin("CA", "CALIFORNIA"), "CA")
.when(upper(col("state_raw")).isin("TX", "TEXAS"), "TX")
.when(upper(col("state_raw")).isin("NY", "NEW YORK"), "NY")
.otherwise(upper(col("state_raw"))))
# Add derived metrics (increases data size with enrichment)
.withColumn("interaction_date", to_date(col("event_timestamp")))
.withColumn("customer_value_tier",
when(col("transaction_amount") > 500, "high_value")
.when(col("transaction_amount") > 100, "medium_value")
.when(col("transaction_amount") > 0, "low_value")
.otherwise("browser_only"))
# Behavioral analytics (adds significant business value)
.withColumn("engagement_score",
expr("case when page_views = 0 then 0 when page_views <= 2 then 1 when page_views <= 5 then 2 when page_views <= 10 then 3 else 4 end"))
# CRITICAL: Keep the large payload columns that maintain dataset size
.withColumn("interaction_payload_clean", col("interaction_payload"))
.withColumn("enriched_payload",
concat_ws("|", col("interaction_payload"), col("full_context_fingerprint"),
expr("cast(unix_timestamp() as string)")))
)That’s just the data transformation logic – cleaning emails, standardizing addresses, adding business metrics. But that innocent Python code won’t run without this supporting infrastructure. Here’s the Spark configuration required to make it actually work at scale:
sparkConf:
# Iceberg and Hive integration
spark.jars.packages: "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1"
spark.sql.extensions: "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"
spark.sql.catalog.ice: "org.apache.iceberg.spark.SparkCatalog"
spark.sql.catalog.ice.type: "hive"
spark.sql.catalog.ice.uri: "thrift://mdp-hive-metastore.md-pipeline.svc.cluster.local:9083"
# S3A performance optimizations
spark.hadoop.fs.s3a.fast.upload: "true"
spark.hadoop.fs.s3a.fast.upload.buffer: "bytebuffer"
spark.hadoop.fs.s3a.multipart.size: "134217728"
spark.hadoop.fs.s3a.connection.maximum: "1024"
spark.hadoop.fs.s3a.threads.max: "512"
# Large payload handling optimizations
spark.sql.parquet.enableVectorizedReader: "false"
spark.sql.parquet.columnarReaderBatchSize: "1024"
spark.sql.adaptive.advisoryPartitionSizeInBytes: "64MB"
# Spark performance tuning for aggregation workload
spark.sql.shuffle.partitions: "4096"
spark.sql.adaptive.enabled: "true"
spark.sql.adaptive.coalescePartitions.enabled: "true"
spark.sql.adaptive.skewJoin.enabled: "true"
# Memory and performance tuning
spark.executor.memoryOverhead: "4096"
spark.driver.memoryOverhead: "4096"
spark.network.timeout: "1800s"
spark.executor.heartbeatInterval: "60s"
# Kubernetes executor management
spark.executor.instances: "32"
spark.kubernetes.allocation.batch.size: "24"
# JVM optimizations for large payloads
spark.executor.extraJavaOptions: "-XX:+UseG1GC -XX:MaxDirectMemorySize=4g -XX:MaxMetaspaceSize=1g"Count those configuration parameters. That’s 25+ settings just to make the silver enrichment stage work reliably. And this is for a “simple” Customer 360 use case!
Databricks doesn’t just run Spark; they’ve built Photon, a vectorized execution engine that delivers lakehouse performance optimizations most teams could never implement themselves. AWS EMR doesn’t just provide Spark clusters; they offer pre-tuned configurations, official Iceberg integration guidance, and mature monitoring tooling that actually works out of the box.
These managed services succeed because they turn the powerful but dangerous Spark component into a reliable data processing product. You’re not paying for compute power – you can get that anywhere. You’re paying for the accumulated wisdom of thousands of production deployments, codified into configurations that don’t require a PhD in distributed systems to understand.
Silli Side note: When I started this exploration, I was firmly convinced I could wrangle raw Spark into submission through sheer determination and tea. Three weeks later, I have a newfound appreciation for why Databricks charges what they do. Some lessons are expensive.
The Hybrid Engine Metaphor Extended
The automotive analogy runs deeper than just complexity. Modern cars have become so sophisticated that independent mechanics increasingly can’t service them. You need specialized diagnostic equipment, proprietary knowledge, and vendor-specific training. Try taking your Tesla to Joe’s Auto Shop, and Joe will look at you like you just asked him to perform heart surgery.

The same dynamic is playing out in data infrastructure. Teams that try to run raw Spark often find themselves spending more time on operational concerns than actual data processing. Memory tuning becomes a specialty. Understanding Catalyst optimizer behavior requires deep expertise. Managing resource contention across multi-tenant clusters demands sophisticated monitoring that doesn’t exist out of the box.
Like that hybrid engine, you technically can open it up and rebuild everything from the ground up. But after enough late nights debugging shuffle spill issues or S3 rate limiting problems (and trust me, there will be many), most organizations conclude they’d rather pay someone else to handle the engine maintenance.
Think of it this way: you could learn to rebuild a transmission, or you could pay a specialist who’s rebuilt thousands of them. The specialist probably won’t screw it up and leave you stranded on the highway at 2 AM. Guess which option your boss prefers when the quarterly earnings call is tomorrow?
Scale-Out Architecture’s Continuing Evolution
The broader lesson extends beyond Spark itself. The fundamental tension between scale-up and scale-out architectures continues to shape data infrastructure decisions, and frankly, it’s not getting any simpler.
Scale-up solutions (powerful single machines, optimized databases) offer simplicity and predictable performance. You know exactly what you’re getting, and when something breaks, there’s usually one place to look. Scale-out solutions (distributed systems, horizontal scaling) offer unlimited capacity but exponential operational complexity. When something breaks in a distributed system, it could be any of 47 different components, and good luck figuring out which one.
Spark sits at the heart of this tension because it’s one of the most successful attempts to make scale-out processing accessible to data teams. But “accessible” is relative. Compared to writing raw MapReduce jobs, Spark is incredibly user-friendly. Compared to running SQL queries against a traditional database, Spark requires significant infrastructure sophistication and personel expertise.
This is why the managed services market for data infrastructure continues to grow rapidly. The underlying technologies are becoming more powerful but also more complex. Organizations want the capabilities without the operational overhead. It’s like wanting a Ferrari but with Honda Civic maintenance requirements. Spoiler alert: physics doesn’t work that way.
The 2025 Scale Out Data Landscape
As we move through 2025, Spark remains the default choice for scale-out data processing, but the ecosystem around it has matured dramatically. The successful deployments aren’t the ones running raw Spark on bare metal (though some masochists still attempt this). They’re the ones that have either invested heavily in operational expertise or chosen managed services that abstract the complexity.
The lakehouse architecture pattern has become the standard, and Spark is the primary engine that makes it work. Whether you’re using Delta Lake, Iceberg, or Hudi, you’re probably running Spark underneath to power the transformations, analytics, and machine learning workloads that define modern data platforms.
Let me show you what a “complete” medallion pipeline actually looks like in practice. This is my gold layer aggregation logic – the business intelligence that executives actually want to see:
# Executive dashboard aggregations
daily_kpis = (df.groupBy("interaction_date")
.agg(
countDistinct("customer_id").alias("daily_active_customers"),
countDistinct("email_clean").alias("unique_email_addresses"),
sum("transaction_amount").alias("total_daily_revenue"),
avg("transaction_amount").alias("avg_transaction_value"),
max("transaction_amount").alias("largest_transaction"),
count(col("transaction_amount") > 0).alias("total_transactions"),
sum(when(col("channel") == "web", col("transaction_amount")).otherwise(0)).alias("web_revenue"),
sum(when(col("channel") == "mobile_app", col("transaction_amount")).otherwise(0)).alias("mobile_revenue"),
sum(when(col("channel") == "store", col("transaction_amount")).otherwise(0)).alias("store_revenue"),
avg("engagement_score").alias("avg_engagement_score"),
avg("time_on_site_seconds").alias("avg_time_on_site"),
count(col("customer_journey_stage") == "conversion").alias("daily_conversions"),
count(col("loyalty_member") == True).alias("loyalty_member_interactions"),
sum("points_earned").alias("total_points_earned"),
sum("points_redeemed").alias("total_points_redeemed"),
countDistinct("support_ticket_id").alias("support_tickets_created"),
avg("satisfaction_score").alias("avg_satisfaction_score"),
count(col("churn_risk_indicator") == "high_risk").alias("high_churn_risk_customers"),
sum("lifetime_value_estimate").alias("total_estimated_ltv")
))That’s business logic that actually makes sense to executives. But supporting this requires a full infrastructure stack. Here’s what the complete deployment looks like:
Infrastructure Components:
# 1. PostgreSQL StatefulSet (24GB RAM, tuned for Hive Metastore)
# 2. Hive Metastore cluster (8GB RAM, connection pooling)
# 3. Trino cluster (coordinator + 8 workers for analytics)
# 4. S3 bucket definitions (bronze, silver, gold, checkpoints)
# 5. Secret management (S3 credentials, database passwords)
# 6. RBAC configurations (service accounts, cluster roles)Resource Scaling by Pipeline Stage:
# Bronze (data ingestion): 64 executors × 32GB = 2TB total memory
# Silver (enrichment): 32 executors × 16GB = 512GB total memory
# Gold (aggregation): 24 executors × 6GB = 144GB total memoryBut here’s the crucial insight that took me way too long to figure out: the companies winning with Spark in 2025 aren’t the ones with the best Spark expertise. They’re the ones who have figured out how to make Spark’s complexity invisible to their data teams, either through sophisticated internal platforms or by leveraging managed services.
Here’s my complete bronze ingestion configuration. This is what “simple” data generation looks like:
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: mdp-bronze-ingest
spec:
mode: cluster
sparkImage:
productVersion: "3.5.6"
mainApplicationFile: local:///opt/scripts/bronze_ingest.py
executor:
cores: 2
memory: 32Gi
env:
- name: MDP_INGEST_GB
value: "1024"
- name: MDP_INGEST_PARTITIONS
value: "768"
- name: MDP_PAYLOAD_KB
value: "256"
sparkConf:
# S3A configuration for maximum throughput
spark.hadoop.fs.s3a.fast.upload: "true"
spark.hadoop.fs.s3a.multipart.size: "268435456"
spark.hadoop.fs.s3a.connection.maximum: "2048"
spark.hadoop.fs.s3a.threads.max: "1024"
spark.sql.shuffle.partitions: "768"
spark.executor.instances: "64"
spark.executor.extraJavaOptions: "-XX:+UseG1GC -XX:MaxDirectMemorySize=8g"
# ... plus 15 more performance tuning parametersNotice how the “simple” customer data generation requires 64 executors with 32GB each, plus dozens of performance tuning parameters.
This is what I mean by Spark being a component, not a product. You’re not just running data transformations – you’re orchestrating a distributed computing platform with dozens of interdependent systems, and then praying nothing breaks accross 00’s to 000’s of pipelines.
Conclusion: Power Requires Respect (And Sometimes Professional Help)
Apache Spark in 2025 remains an incredible piece of technology. It can process petabytes of data, unify batch and streaming workloads, and power sophisticated machine learning pipelines. Its flexibility and performance continue to make it indispensable for modern data infrastructure. When it works, it’s beautiful. When it doesn’t, it’s expensive.
But respect the gloves. Spark’s power comes with operational complexity that can overwhelm teams unprepared for the challenges. The most successful Spark deployments in 2025 are the ones that acknowledge this complexity and build appropriate abstractions around it.
Silli Wisdom: Whether that’s investing in deep internal expertise (good luck hiring those people), adopting comprehensive operator platforms like Stackable (prepare for a learning curve), or choosing fully managed services like Databricks (prepare for a different kind of learning curve on your credit card statement), the key is recognizing that raw Spark is a component, not a product. The magic happens in the integration layer, and that’s where the real value of modern data platforms lies.